| MPI2007 license: | 1 | Test date: | Oct-2017 |
|---|---|---|---|
| Test sponsor: | HPE | Hardware Availability: | Jul-2017 |
| Tested by: | HPE | Software Availability: | Nov-2017 |
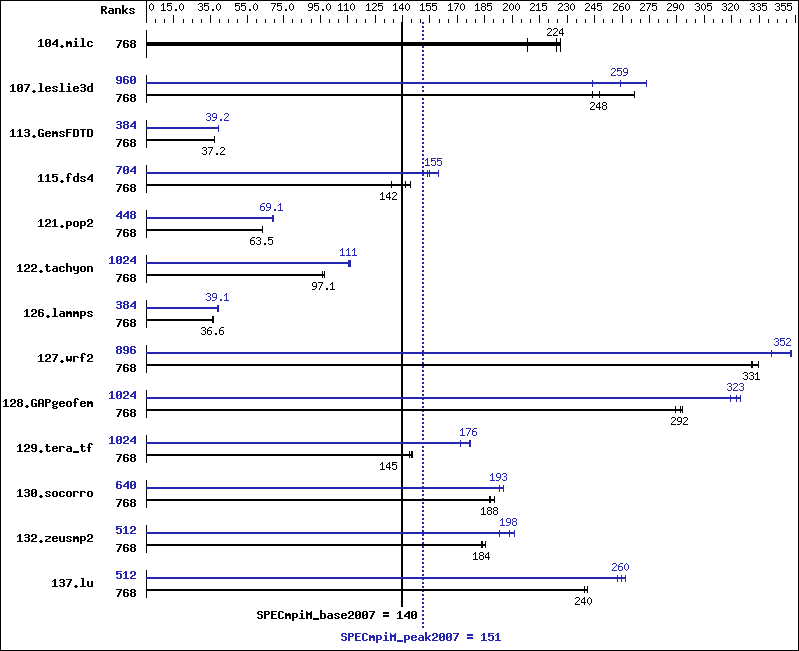
Results Table
| Benchmark | Base | Peak | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ranks | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | Ranks | Seconds | Ratio | Seconds | Ratio | Seconds | Ratio | |
| Results appear in the order in which they were run. Bold underlined text indicates a median measurement. | ||||||||||||||
| 104.milc | 768 | 7.51 | 208 | 6.91 | 226 | 6.99 | 224 | 768 | 7.51 | 208 | 6.91 | 226 | 6.99 | 224 |
| 107.leslie3d | 768 | 21.4 | 244 | 21.1 | 248 | 19.5 | 267 | 960 | 20.1 | 259 | 21.4 | 244 | 19.1 | 273 |
| 113.GemsFDTD | 768 | 169 | 37.2 | 169 | 37.2 | 170 | 37.2 | 384 | 160 | 39.3 | 161 | 39.2 | 161 | 39.2 |
| 115.fds4 | 768 | 14.6 | 134 | 13.5 | 144 | 13.8 | 142 | 704 | 12.2 | 160 | 12.7 | 154 | 12.6 | 155 |
| 121.pop2 | 768 | 65.0 | 63.5 | 65.2 | 63.3 | 65.0 | 63.5 | 448 | 59.6 | 69.3 | 59.8 | 69.0 | 59.7 | 69.1 |
| 122.tachyon | 768 | 28.8 | 97.1 | 28.8 | 97.2 | 29.1 | 96.2 | 1024 | 25.3 | 111 | 25.4 | 110 | 25.1 | 111 |
| 126.lammps | 768 | 79.6 | 36.6 | 80.7 | 36.1 | 79.6 | 36.6 | 384 | 74.5 | 39.1 | 74.2 | 39.3 | 75.3 | 38.7 |
| 127.wrf2 | 768 | 23.3 | 335 | 23.5 | 331 | 23.5 | 331 | 896 | 22.1 | 353 | 22.1 | 352 | 22.8 | 342 |
| 128.GAPgeofem | 768 | 7.07 | 292 | 7.05 | 293 | 7.14 | 289 | 1024 | 6.47 | 319 | 6.36 | 325 | 6.40 | 323 |
| 129.tera_tf | 768 | 19.0 | 146 | 19.2 | 144 | 19.1 | 145 | 1024 | 15.7 | 176 | 15.6 | 177 | 16.1 | 172 |
| 130.socorro | 768 | 20.3 | 188 | 20.1 | 190 | 20.4 | 187 | 640 | 19.8 | 193 | 19.8 | 193 | 19.6 | 195 |
| 132.zeusmp2 | 768 | 16.9 | 183 | 16.7 | 185 | 16.9 | 184 | 512 | 16.1 | 193 | 15.4 | 201 | 15.6 | 198 |
| 137.lu | 768 | 15.4 | 239 | 15.2 | 241 | 15.3 | 240 | 512 | 14.3 | 257 | 14.2 | 260 | 14.0 | 262 |
| Hardware Summary | |
|---|---|
| Type of System: | Homogeneous |
| Compute Node: | HPE XA730i Gen10 Server Node |
| Interconnect: | InfiniBand (MPI and I/O) |
| File Server Node: | Lustre FS |
| Total Compute Nodes: | 32 |
| Total Chips: | 64 |
| Total Cores: | 1280 |
| Total Threads: | 2560 |
| Total Memory: | 6 TB |
| Base Ranks Run: | 768 |
| Minimum Peak Ranks: | 384 |
| Maximum Peak Ranks: | 1024 |
| Software Summary | |
|---|---|
| C Compiler: | Intel C Composer XE for Linux, Version 18.0.0.128 Build 20170811 |
| C++ Compiler: | Intel C++ Composer XE for Linux, Version 18.0.0.128 Build 20170811 |
| Fortran Compiler: | Intel Fortran Composer XE for Linux, Version 18.0.0.128 Build 20170811 |
| Base Pointers: | 64-bit |
| Peak Pointers: | 64-bit |
| MPI Library: | HPE Performance Software - Message Passing Interface 2.17 |
| Other MPI Info: | OFED 3.2.2 |
| Pre-processors: | None |
| Other Software: | None |
Node Description: HPE XA730i Gen10 Server Node
| Hardware | |
|---|---|
| Number of nodes: | 32 |
| Uses of the node: | compute |
| Vendor: | Hewlett Packard Enterprise |
| Model: | SGI 8600 (Intel Xeon Gold 6148, 2.40 GHz) |
| CPU Name: | Intel Xeon Gold 6148 |
| CPU(s) orderable: | 1-2 chips |
| Chips enabled: | 2 |
| Cores enabled: | 40 |
| Cores per chip: | 20 |
| Threads per core: | 2 |
| CPU Characteristics: | Intel Turbo Boost Technology up to 3.70 GHz |
| CPU MHz: | 2400 |
| Primary Cache: | 32 KB I + 32 KB D on chip per core |
| Secondary Cache: | 1 MB I+D on chip per core |
| L3 Cache: | 27.5 MB I+D on chip per chip |
| Other Cache: | None |
| Memory: | 192 GB (12 x 16 GB 2Rx4 PC4-2666V-R) |
| Disk Subsystem: | None |
| Other Hardware: | None |
| Adapter: | Mellanox MT27700 with ConnectX-4 ASIC |
| Number of Adapters: | 2 |
| Slot Type: | PCIe x16 Gen3 8GT/s |
| Data Rate: | InfiniBand 4X EDR |
| Ports Used: | 1 |
| Interconnect Type: | InfiniBand |
| Software | |
|---|---|
| Adapter: | Mellanox MT27700 with ConnectX-4 ASIC |
| Adapter Driver: | OFED-3.4-2.1.8.0 |
| Adapter Firmware: | 12.18.1000 |
| Operating System: | Red Hat Enterprise Linux Server 7.3 (Maipo), Kernel 3.10.0-514.2.2.el7.x86_64 |
| Local File System: | LFS |
| Shared File System: | LFS |
| System State: | Multi-user, run level 3 |
| Other Software: | SGI Management Center Compute Node 3.5.0, Build 716r171.rhel73-1705051353 |
Node Description: Lustre FS
| Hardware | |
|---|---|
| Number of nodes: | 4 |
| Uses of the node: | fileserver |
| Vendor: | Hewlett Packard Enterprise |
| Model: | Rackable C1104-GP2 (Intel Xeon E5-2690 v3, 2.60 GHz) |
| CPU Name: | Intel Xeon E5-2690 v3 |
| CPU(s) orderable: | 1-2 chips |
| Chips enabled: | 2 |
| Cores enabled: | 24 |
| Cores per chip: | 12 |
| Threads per core: | 1 |
| CPU Characteristics: | Intel Turbo Boost Technology up to 3.50 GHz Hyper-Threading Technology disabled |
| CPU MHz: | 2600 |
| Primary Cache: | 32 KB I + 32 KB D on chip per core |
| Secondary Cache: | 256 KB I+D on chip per core |
| L3 Cache: | 30 MB I+D on chip per chip |
| Other Cache: | None |
| Memory: | 128 GB (8 x 16 GB 2Rx4 PC4-2133P-R) |
| Disk Subsystem: | 684 TB RAID 6 48 x 8+2 2TB 7200 RPM |
| Other Hardware: | None |
| Adapter: | Mellanox MT27700 with ConnectX-4 ASIC |
| Number of Adapters: | 2 |
| Slot Type: | PCIe x16 Gen3 |
| Data Rate: | InfiniBand 4X EDR |
| Ports Used: | 1 |
| Interconnect Type: | InfiniBand |
| Software | |
|---|---|
| Adapter: | Mellanox MT27700 with ConnectX-4 ASIC |
| Adapter Driver: | OFED-3.3-1.0.0.0 |
| Adapter Firmware: | 12.14.2036 |
| Operating System: | Red Hat Enterprise Linux Server 7.3 (Maipo), Kernel 3.10.0-514.2.2.el7.x86_64 |
| Local File System: | ext3 |
| Shared File System: | LFS |
| System State: | Multi-user, run level 3 |
| Other Software: | None |
Interconnect Description: InfiniBand (MPI and I/O)
| Hardware | |
|---|---|
| Vendor: | Mellanox Technologies and SGI |
| Model: | SGI P0002145 |
| Switch Model: | SGI P0002145 |
| Number of Switches: | 4 |
| Number of Ports: | 36 |
| Data Rate: | InfiniBand 4X EDR |
| Firmware: | 11.0350.0394 |
| Topology: | Enhanced Hypercube |
| Primary Use: | MPI and I/O traffic |
Base Tuning Notes
src.alt used: 129.tera_tf->add_rank_support src.alt used: 130.socorro->nullify_ptrs
Submit Notes
The config file option 'submit' was used.
General Notes
Software environment: export MPI_CONNECTIONS_THRESHOLD=0 export MPI_REQUEST_MAX=65536 export MPI_TYPE_MAX=32768 export MPI_IB_RAILS=2 export MPI_IB_IMM_UPGRADE=false export MPI_IB_DCIS=2 export MPI_IB_HYPER_LAZY=false ulimit -s unlimited BIOS settings: AMI BIOS version SAED7177, 07/17/2017 Job Placement: Each MPI job was assigned to a topologically compact set of nodes. Additional notes regarding interconnect: The Infiniband network consists of two independent planes, with half the switches in the system allocated to each plane. I/O traffic is restricted to one plane, while MPI traffic can use both planes.
Base Compiler Invocation
C benchmarks:
| icc |
C++ benchmarks:
| 126.lammps: | icpc |
Fortran benchmarks:
| ifort |
Benchmarks using both Fortran and C:
| icc ifort |
Base Portability Flags
| 121.pop2: | -DSPEC_MPI_CASE_FLAG |
| 127.wrf2: | -DSPEC_MPI_CASE_FLAG -DSPEC_MPI_LINUX |
| 130.socorro: | -assume nostd_intent_in |
Base Optimization Flags
C benchmarks:
| -O3 -xCORE-AVX512 -no-prec-div -ipo |
C++ benchmarks:
| 126.lammps: | -O3 -xCORE-AVX512 -no-prec-div -ansi-alias -ipo |
Fortran benchmarks:
| -O3 -xCORE-AVX512 -no-prec-div -ipo |
Benchmarks using both Fortran and C:
| -O3 -xCORE-AVX512 -no-prec-div -ipo |
Base Other Flags
C benchmarks:
| -lmpi |
C++ benchmarks:
| 126.lammps: | -lmpi |
Fortran benchmarks:
| -lmpi |
Benchmarks using both Fortran and C:
| -lmpi |
Peak Compiler Invocation
C benchmarks:
| icc |
C++ benchmarks:
| 126.lammps: | icpc |
Fortran benchmarks:
| ifort |
Benchmarks using both Fortran and C (except as noted below):
Peak Portability Flags
Same as Base Portability Flags
Peak Optimization Flags
C benchmarks:
| 104.milc: | basepeak = yes |
| 122.tachyon: | -O3 -xCORE-AVX512 -no-prec-div -ipo |
C++ benchmarks:
| 126.lammps: | -O3 -xCORE-AVX512 -no-prec-div -ansi-alias -ipo |
Fortran benchmarks:
| -O3 -xCORE-AVX512 -no-prec-div -ipo |
Benchmarks using both Fortran and C:
| -O3 -xCORE-AVX512 -no-prec-div -ipo |
Peak Other Flags
Same as Base Other Flags