SPECweb99 Release 1.02
July 21, 2000
|
SPECweb99 Release 1.02July 21, 2000 |
1.0 Overview
2.0 Logical Components of
SPECweb99
4.1 Architecture
4.2 MSS, Rated Receive, and Simultaneous Connections
4.3 Implementation
4.4 Flow Diagram
4.5 Static Workload
4.6 Dynamic Workload
5.0 Keep-Alive/Persistent Connection Requests
6.0 Percentage of Requests in the workload
7.0 Conclusion
SPECweb99 is a software benchmark product developed by the Standard Performance Evaluation Corporation (SPEC), a non-profit group of computer vendors, system integrators, universities, research organizations, publishers, and consultants. It is designed to measure a system's ability to act as a web server servicing static and dynamic page requests.
SPECweb99 is the successor
of SPECweb96, and continues the tradition of giving Web users the most
objective and most representative benchmark for measuring web server performance. Web
server usage patterns have changed considerably since the release of SPECweb96.
SPECweb99 uses a workload that is more relevant to current web usage patterns
(such as the use of dynamic content and persistent connections). This paper
will discuss the benchmark architecture; the workload used in the benchmark,
the performance metric, and the steps needed to run the benchmark on a
given configuration.
SPECweb99 has been completely
redesigned from the ground up. It has a new test scaffold completely different
from the one used in SPECweb96. The benchmark supports both HTTP 1.0 and
HTTP 1.1 protocols. The two major logical components of the benchmark are
given below:
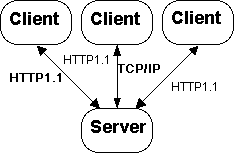
Also known as the "load generator" and refers to the application program that establishes connections for the purpose of sending and receiving HTTP requests. In a client/server configuration this software resides on the client machine. Physically, it refers to the client machine running the load generator application.
The server is that collection of hardware and software that handles the requests issued by the clients. In this documentation, we shall refer to it as SUT (System Under Test) or Web Server. The HTTP server software may also be referred to as the HTTP daemon.
The performance metric used
for reporting benchmark results is SPECweb99. SPECweb99 measures the maximum
number of simultaneous connections, requesting the predefined benchmark
workload that a web server is able to support while still meeting specific
throughput and error rate requirements. The connections are made and sustained
at a specified maximum bit rate with a maximum segment size intended to
more realistically model conditions that will be seen on the Internet during
the lifetime of this benchmark.
Under the terms of the SPECweb99 license, SPECweb99
results may not be publicly reported unless they are run in compliance
with the SPEC run rules. Results published at the SPEC web site have been
reviewed and approved by the SPECweb committee. The run and reporting rules
may be found on the SPEC web site or on the SPECweb99 distribution. SPEC's
web site also contains benchmark results published by SPEC members and
other SPECweb99 licensees. For more information on publishing results at
the SPEC web site, please send e-mail to: info@spec.org
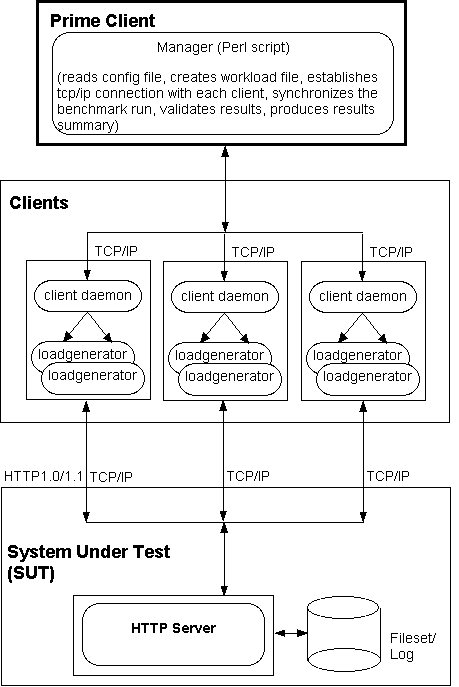
SPECweb99 is a benchmark used to measure the performance of HTTP servers. It uses one or more client systems to create the HTTP workload for the server. Each client sends HTTP requests to the server and then validates the response received. At the end of the benchmark run, the data from all the clients is collected by the prime client. The prime client uses this data to calculate aggregate bit rate for the test and determine the number of simultaneous connections that conform to the specified bit rate limits.
Prior to the start of the benchmark, a client daemon is started on all the client systems. This client daemon listens on a specified port for requests from the prime client machine. The prime client machine is the system from which the benchmark is invoked.
The benchmark is started by invoking a script called manager on the prime client machine. The manager script first parses all the parameters in the supplied configuration file. Next it opens up a TCP/IP socket to each of the client systems and handshakes with the client daemon running on the system. The workload file is transferred and the configuration information is sent. At this point, each client starts up all of its children (also known as load generators) and waits for a start message from the manager.
The manager is responsible for synchronizing the different states of the benchmark across all the client systems. As soon as the clients get the start message from the manager, the load generators on the client systems start running and generating the requested load. The current state (SETUP, SYNC, RAMPUP, RAMPDOWN, SHUTDOWN, and RESULT) is maintained by the controlling thread on each client. After all of the load generators have completed issuing the requests associated with each test point, the state moves to RESULT. At this point, the manager requests the results from all the clients, sums up the data and reports the test results for that iteration. The connection to the client systems is then closed. This process is repeated 3 times for a reported result.
When the final test point has completed (SHUTDOWN), the prime determines if the run is complete and valid. A complete report containing the summary, results, overall metric, and configuration information is then generated. The SPECweb99 metric is the median result for the 3 iterations.
SPECweb99 uses a rated receive mechanism for simulating 400,000 bits/sec connections to an Internet Service Provider. In addition, SPECweb99 requires that the connections between a SPECweb99 load generating machine and the SUT must not use a TCP Maximum Segment Size (MSS) greater than 1460 bytes. This needs to be accomplished by platform-specific means outside the benchmark code itself.
The main reason for adopting the controlled MSS in SPECweb99 is to allow us to have the MSS distribution that more closely matches what an Internet web server is likely to see. At the same time, this minimizes the issues with different link MTU's and servers being connected to the rest of the world via interconnect devices.
The SPECweb99 metric represents the actual number of simultaneous connections that a server can support. In the benchmark, a number of simultaneous connections are requested. For each simultaneous connection, there is a process or thread created to generate workload for the benchmark. Each of these processes/threads sends HTTP requests to the SUT in a contiguous manner.
The SPECweb99 metric is implemented by measuring the maximum number of load generating threads of execution that are retrieving URLs between a maximum of 400,000 bits per second (50000 bytes/sec) and a minimum of 320,000 bits per second (40000 bytes/sec).
Each HTTP request takes a certain amount of elapsed time to complete depending on the file size. SPECweb99 enforces the client to read responses in chunks of 1460 (MSS) bytes or less. Theoretically, a 1460 byte chunk of data over a 400,000 bits per second line would arrive every 0.03 seconds. Since the implementation does not actually restrict the line speed of the connection, arrival time calculations are used to determine how long the operation should take at 400,000 bits per second. This calculated operation duration is enforced by sleeping at the end of the operation.
Over the lifetime of a simultaneous connection, there are HTTP requests one after another each last for a variable length of elapsed time. The simultaneous connection will be measured by the aggregate bit rate of all the bytes it has received from the SUT, over the sum of the elapsed time of these HTTP requests.
A simultaneous connection
is considered conforming to the required bit rate if its aggregate bit
rate is more than 320,000 bites/second, or 40,000 bytes/second. If a simultaneous
connection does not conform to this minimum bit rate, or its aggregate
bit rate falls below 320,000 bites/second, it is not counted in the metric.
|
In addition, a load generator
is considered valid if the following criteria are met:
1) The load generator must have at least one successful OP in all the four workload classes (for details see section: Static Workload).
2) The load generator
has detected less than 1% error for every workload class.
The configuration file (rc)
parameters that affect the load generator are:
Please note that the variables: USER_LINE_SPEED and USER_SPEED_LIMIT are fixed for the benchmark and any change will produce an "INVALID" SPECweb99 result.
The static portion of the workload models a hypothetical web provider. The web provider allocates a given amount of space for each of its "members" to place their web pages. Each member has his own web space on the server and a number of different pages within that space.
The pages are represented by files of different sizes that are accessed with different frequencies. The file sizes and access frequencies have been selected by looking at log files from NCSA, HP, HAL Computers and even a Comics Web site. Based on this information, the benchmark uses a workload consisting of files in four classes. The frequency of distribution is shown in the table below:
|
Workload Class |
File size |
Target Mix |
| Class 0 | less than 1K | 35% |
| Class 1 | less than 10K | 50% |
| Class 2 | less than 100K | 14% |
| Class 3 | less than 1000K | 1% |
Due to the fact that larger web servers are expected to service more files, the size of the workload file set is a function of the requested number of simultaneous connections. This is to maintain some degree of reality as some one purchasing a fast server has greater expectations of how many files can be served at any given time.
The workload file set consists
of a number of directories. Each directory contains 9 files per class,
36 files in total. The files in Class 0 are in increments of 0.1K, those
in Class 1 are in increments of 1K, those in Class 2 are in increments
of 10K, and those in Class 3 are in increments of 100K in size. This requires
approximately 4.8 MB of disk space per directory. The number of directories
that are created is computed using the formula given below:
During a benchmark run, a
Zipf distribution is used to access each directory. A Zipf distribution
is a distribution where the probability of selecting the nth item is proportional
to 1/n. Zipf distributions are empirically associated with situations where
there are many equal-cost alternatives (e.g., referring to books in a library,
borrowing movies at a video store).
Within a directory, the four classes are chosen using a fixed distribution that conforms to the class mix percentage described in Table 1-1. A card deck algorithm consisting of 1000 cards is used to implement this percentage mix.
Each file within a class is accessed using a Zipf distribution. Under the Zipf distribution the most popular to least popular files are 4,3,5,2,6,1,7,8,0 and the relative hits are shown below:
The model for dynamic content in SPECweb99 is based on two prevalent feature of Commercial Web servers -- advertising and user registration. Many web servers use programs to generate content for prominent pages "on the fly", so that ad space can be sold to several different customers, and rotated in real time. Increasingly, web servers also use browser-specific information to tailor pages and advertisements to the viewer.
There are four kinds of
dynamic content requests in the benchmark:
The Standard Dynamic GET and Standard Dynamic CGI GET request simulate simple ad rotation on a commercial web server. Many web servers use dynamic scripts to generate content for ads on web pages "on the fly", so that ad space can be sold to different customers and rotated in real time. the file containing the script will be invoked as an executable program.
The Standard Dynamic CGI GET request must use a non-persistent implementation such that a new process is created each time a request is received (e.g. fork for Unix and CreateProcess for NT). CGI accelerators and Fast-CGI, which use persistent processes or threads, may not be used to implement the Standard Dynamic CGI GET function. According to the CGI 1.1 draft specification, the CGI script is invoked in a system defined manner and unless otherwise specified, the file containing the CGI script will be invoked as an executable program. The SPECweb99 run rules requires the stringent implementation described above.
In addition, the Standard Dynamic GET is used for two "housekeeping" functions needed during the benchmark, Reset and Fetch. The pseudo-code for these operations is described in the Housekeeping Pseudo-code section.
The SPECweb99 benchmark uses 2 housekeeping functions to run the test. They are invoked using a dynamic GET. The code to implement them may be in a separate module from any other code for the benchmark. Before the test, a Reset function is invoked to clear/reset some files. After the test, a Fetch function is used to retrieve the PostLog.
The Dynamic GET with Custom Ad Rotation scheme models the tracking of users and their preferences to provide customized ads for their viewing. In the SPECweb99 implementation, a user's ID number is passed as a Cookie along with the ID number of the last ad seen by that user. The user's User Personality record is retrieved and compared against demographic data for ads in the Custom Ad database, starting at the record after the last ad seen. When a suitable match is found, the ad data is returned in a Cookie.
In addition to the Cookies, the request contains a filename to return. Depending on the name of the file to return, it is either returned as is (just like the Standard Dynamic GET request) or it is scanned for a template string and returned with the template filled in with customized information.
The Dynamic POST request models user registration at an ISP site. In the implementation, the POST data and some other information is written to a single ASCII file, the PostLog.
It is the intent of SPEC that the implementation of the dynamic POST functionality be such that the post operation can be validated at any time during the benchmark run by any client issuing a subsequent dynamic request after a POST request.
All POST requests contain a Cookie value that is written into the post log and also sent back to the requester with a Set-Cookie header.
The sample dynamic script implemented in Perl is provided as part of the initial release, and can not be modified. Vendors are allowed to use any API as long as it follows the functional specification for each of the three dynamic requests. Vendors are required to submit to SPEC the source code of their particular implementation along with the submission and license to freely redistribute. The code shall be reviewed by the committee to make sure it does not violate the spirit of the benchmark. SPEC will maintain a repository of the accepted code and will make the code available to requesters.
70% of all requests are either HTTP 1.0 requests with a Connection: Keep-Alive header or HTTP 1.1 requests which use persistent connections by default. The selection of either HTTP 1.0 or HTTP 1.1 as the primary protocol for the test is based on testing the server directly at the start of the run. Alternately, the benchmarker can set the HTTP_PROTOCOL parameter in the rc file to select the primary protocol. A discrete uniform distribution with a range of 5 to 15 inclusive and a mean of 10 is used to generate the number of Keep-Alive or Persistent Connection requests per connection.
The remaining 30% of requests are HTTP 1.0 requests issued without the Connection: Keep-Alive header (i.e. non-persistent). Note that for these requests the server is required to close the connection and this will cause the TCP TIME-WAIT states to accrue on the server.
The table below summarizes the different types of requests and their respective percentages in the workload mix.
|
|
|
| Static GET | 70 |
| Standard Dynamic GET | 12.45 |
| Standard Dynamic GET (CGI) | 0.15 |
| Customized Dynamic GET | 12.6 |
| Dynamic POST | 4.8 |
| Total | 100 |
SPECweb99 represents a standardized benchmark for measuring web server performance. Building upon the success of SPECweb96, SPECweb99 provides users an objective measure allowing users to make fair comparisons between results from a wide range of systems.
SPECweb99 includes an updated workload and it also comes with a completely redesigned test harness. The new workload includes support for dynamic content generation and support for HTTP 1.1. Even though SPECweb99 is not designed as a capacity-planning tool, it does provide valuable information on how web servers handle the workload mix.
This whitepaper has described the benchmark architecture. It is not a guide to running the benchmark. For information on running the benchmark please refer to the User Guide included with the benchmark CD. Also, please refer to the Run Rules that govern what constitutes a valid SPECweb99 run prior to running tests whose results will be submitted to SPEC for publication on the SPEC web site or publicly disclosed as a valid SPECweb99 result.
More information on SPECweb99
can be found at the SPEC web site at: