SPECsfs2008_nfs.v3 Result
|
Hewlett-Packard Company
|
:
|
BL860c i2 4-node HA-NFS Cluster
|
|
SPECsfs2008_nfs.v3
|
=
|
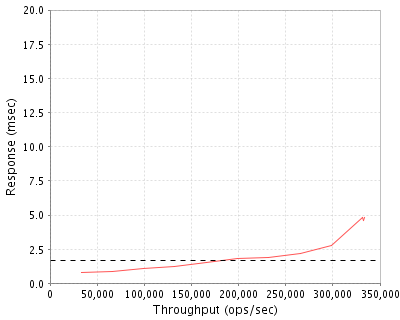
333574 Ops/Sec (Overall Response Time = 1.68 msec)
|
Performance
Throughput
(ops/sec)
|
Response
(msec)
|
|
33021
|
0.8
|
|
66090
|
0.9
|
|
99232
|
1.1
|
|
132331
|
1.2
|
|
165550
|
1.5
|
|
198590
|
1.8
|
|
232214
|
1.9
|
|
265379
|
2.2
|
|
298770
|
2.8
|
|
331234
|
4.8
|
|
332159
|
4.6
|
|
333574
|
4.8
|
|
|
Product and Test Information
|
Tested By
|
Hewlett-Packard Company
|
|
Product Name
|
BL860c i2 4-node HA-NFS Cluster
|
|
Hardware Available
|
July 2010
|
|
Software Available
|
July 2010
|
|
Date Tested
|
April 2010
|
|
SFS License Number
|
3
|
|
Licensee Locations
|
Cupertino, CA
USA
|
The HP BL860c i2 4-node HA-NFS cluster is a high performance and highly available blade server cluster with the ability to provide combined fileserver, database, and compute services to high-speed Ethernet networks. HP's blade technology provides linear scale-out processing from a single node to many nodes either within a single blade enclosure or across enclosures. The HP-UX operating system combined with HP's Serviceguard software provides continuous availability of the cluster providing transparent fail-over of nodes in the event of a node failure. Each individual blade node is highly available as well, providing redundant network and storage interfaces that fail-over transparently while still being able to maintain high I/O throughput. In addition, Double Chip Spare technology is used to assure node resilience in the face of memory module failures. At only 10U high, the c7000 chassis utilized in this cluster provides a very dense and energy efficient enclosure that is capable of delivering high I/O throughput. The MSA2324fc arrays providing storage in the benchmark are very reliable, very dense and deliver excellent throughput. Each MSA2324fc holds up to 99 high performance disk drives in only 8U of rack space. Unlike proprietary NFS solutions, HP's HA-NFS blade cluster solution is very flexible in that any HP supported Fibre Channel connected storage can be used and the blade nodes don't need to be dedicated solely to providing NFS services.
Configuration Bill of Materials
|
Item No
|
Qty
|
Type
|
Vendor
|
Model/Name
|
Description
|
|
1
|
1
|
Blade Chassis
|
HP
|
c7000
|
10U blade chassis with 10 fans, 6 power supplies, and dual management modules
|
|
2
|
4
|
Blade Server
|
HP
|
BL860c i2
|
Integrity BL860c i2 blade server with 192GB of memory
|
|
3
|
8
|
Disk Drive
|
HP
|
512547-B21
|
HP 146GB 6Gbit 15K RPM SAS 2.5 inch small form factor dual-port hard disk drive
|
|
4
|
8
|
Disk controller
|
HP
|
451871-B21
|
QLogic QMH2562 8Gb FC HBA for HP C-Class BladeSystem
|
|
5
|
4
|
FC Switch
|
HP
|
AJ821A
|
HP B-Series 8Gbit 24-port SAN switch for BladeSystem c-Class
|
|
6
|
2
|
Network Module
|
HP
|
455880-B21
|
HP Virtual Connect Flex-10 10Gb Ethernet Module for the BladeSystem c-Class
|
|
7
|
16
|
FC Disk Array
|
HP
|
MSA2324fc G2
|
HP StorageWorks dual controller Modular Smart Array with 24 small form factor SAS disk bays
|
|
8
|
48
|
Disk Storage Tray
|
HP
|
MSA70
|
HP StorageWorks disk storage bay with 25 small form factor SAS disk bays including a dual-domain I/O module for redundancy
|
|
9
|
1472
|
Disk Drive
|
HP
|
418371-B21
|
HP 72GB 3Gbit 15K RPM SAS 2.5 inch small form factor dual-port hard disk drive
|
Server Software
|
OS Name and Version
|
HP-UX 11iv3 March 2010 Update High Availabilty OE
|
|
Other Software
|
none
|
|
Filesystem Software
|
VxFS 5.0
|
Server Tuning
|
Name
|
Value
|
Description
|
|
filecache_min
|
50
|
Minimum percentage of memory to use for the filecache. Set using kctune
|
|
filecache_max
|
50
|
Maximum percentage of memory to use for the filecache. Set using kctune
|
|
fs_meta_min
|
1
|
Minimum percentage of memory to use for the filesystem metadata pool. Set using kctune
|
|
vx_ninode
|
6200000
|
Maximum number of inodes to cache. Set using kctune
|
|
vxfs_bc_bufhwm
|
14500000
|
Maximum amount of memory (in bytes) to use for caching VxFS metadata. Set using kctune
|
|
lcpu_attr
|
1
|
Enable Hyper-Threading. Set using kctune
|
|
fcache_seqlimit_system
|
0
|
Limit caching of sequential accesses to 0% of the filecache. Set using kctune
|
|
fcache_seqlimit_file
|
0
|
Limit caching of sequential accesses to 0% of a file. Set using kctune
|
|
fcache_seqlimit_scope
|
3
|
Limit seqlimit tunables to append only accesses. Set using kctune
|
|
base_pagesize
|
8
|
Set the OS minimum pagesize in kilobytes. Set using kctune
|
|
numa_mode
|
1
|
Set the OS operating mode to LORA (Locality-Optimized Resource Alignment). Set using kctune
|
|
fcache_vhand_ctl
|
10
|
Set how aggressively the vhand process flushes dirty pages to disk. Set using kctune
|
|
kmem_aggressive_caching
|
10
|
Set how aggressively the kernel uses large pages for kernel data. Set using kctune
|
|
physpage_page_policy
|
1
|
Set the physical memory page selection policy to favor keeping large pages over cached data. Only supported values are 0 and 1. Set using kctune
|
|
sched_thread_affinity
|
1
|
Set scheduler thread affinity to allow threads to run immediately vs favoring affinity towards a processor. Set using kctune
|
|
vx_idelxwri_timelag
|
0x7fffffff
|
Set interval for flushing delayed extending writes to its maximum. Set using adb
|
|
max_q_depth
|
64
|
Set the disk device queue depth via scsimgr.
|
|
Number of NFS Threads
|
512
|
The number of NFS threads has been increased to 512 by editing /etc/default/nfs.
|
|
tcp_recv_hiwater_def
|
1048567
|
Maximum TCP receive window size in bytes. Set on boot via /etc/rc.config.d/nddconf
|
|
tcp_xmit_hiwater_def
|
1048567
|
Amount of unsent data that triggers write-side flow control in bytes. Set on boot via /etc/rc.config.d/nddconf
|
|
socket_enable_tops
|
0
|
Disable thread optimized packet scheduling. Set on boot via /etc/rc.config.d/nddconf
|
|
rx_timer
|
250
|
Time in microseconds to wait to generate an interrupt for network receives (receive coalescing). Set on boot via /etc/rc.config.d/hpiexgbeconf for each interface card
|
|
tx_timer
|
500
|
Time in microseconds to wait to generate an interrupt for network transmissions (transmit coalescing). Set on boot via /etc/rc.config.d/hpiexgbeconf for each interface card
|
|
memconfig
|
1
|
Set the server memory configuration to interleave memory among all sockets. Set at EFI with memconfig command
|
|
noatime
|
on
|
Mount option added to all filesystems to disable updating of access times.
|
Server Tuning Notes
The kernel patch PHKL_41005 is needed to set the kmem_aggressive_caching and fcache_seqlimit_scope tunables. This patch will be available by July 26, 2010. The web ONCplus depot version B11.31.09.02 was used for the NFS subsystem and will be avilable by July 26, 2010. The March 2010 Web Release of the FCD (Fibre Channel) driver was used (version B.11.31.1003.01). The June 2010 Web Release of the iexgbe (10Gbit) driver was used. Device read-ahead was disabled on the MSA2324fc array by using the command "set cache-parameters read-ahead-size disabled" via the array's CLI on each exported LUN. The intctl command was used to evenly distribute network interrupts among logical cpus 2, 4, 8, and 10 and spread FC interrupts among logical cpus 0, 6, 12, and 14 on each node.
Disks and Filesystems
|
Description
|
Number of Disks
|
Usable Size
|
|
LVM mirrored boot disks for system use only. There are two 146GB 2.5" 15K RPM SAS disks per node.
|
8
|
573.0 GB
|
|
96 72GB 2.5" 15K RPM disks per 12 MSA2324fc arrays, bound into six 16 disk RAID10 LUNs striped in 64KB chunks. 80 72GB 2.5" 15K RPM disks per 4 MSA2324fc arrays, bound into five 16 disk RAID10 LUNs striped in 64KB chunks. A total of 92 sixteen drive LUNs were exported for use. All data filesystems reside on these disks.
|
1472
|
51.4 TB
|
|
Total
|
1480
|
52.0 TB
|
|
Number of Filesystems
|
16
|
|
Total Exported Capacity
|
51.4 TB
|
|
Filesystem Type
|
VxFS
|
|
Filesystem Creation Options
|
-b 8192
|
|
Filesystem Config
|
A set of 4 filesystems are striped in 1MB chunks across 23 LUNs (368 disks) using HP-UX's Logical Volume Manager. There are 4 sets of 4 filesystems in all with each set of 4 filesystems using a different set of 23 LUNs.
|
|
Fileset Size
|
38910.3 GB
|
The storage is comprised of twelve 96 drive and four 80 drive HP MSA2324fc disk arrays. Each array consists of a main unit that holds dual controllers and bays for 24 2.5" SAS disks. Three, 2U, MSA70 SAS drive shelves are then daisy chained from the MSA2324fc to add addition 2.5" SAS drives. All drives are dual-ported and each MSA70 has two paths back to the MSA2324fc for redundancy (one to each controller). Each redundant MSA2324fc controller then has a 4Gbit Fibre Channel connection to a blade chassis FC switch. One controller connects to one FC switch and the other controller connects to another FC switch for redundancy. Each array controller is the primary owner of two to three of the array's five to six LUNs. In the event of a controller failure or FC link failure, LUN ownership is transfered to the other controller. HP's Logical Volume Manager (LVM) was used to combine twenty-three array LUNs together to form a volume group. LUNs were chosen to evenly spread them among all 16 of the arrays. Four logical volumes of identical size were created from each volume group, by striping over each LUN in the volume group using 1MB chunks. A filesystem was created on each logical volume (4 per volume group, 16 in all). A volume group and the filesystems on it are owned by a specific node. In case of a node failure, the volume group and filesystems owned by that node are transfered to another node in the cluster. Once the failing node recovers, its volume group and filesystems are migrated back to it. The migration of volume groups and filesystems are transparent to the remote users of the filesystems. All nodes are able to see all of the LUNS in the configuration at the same time. A subset of the LUNS are owned by any one node.
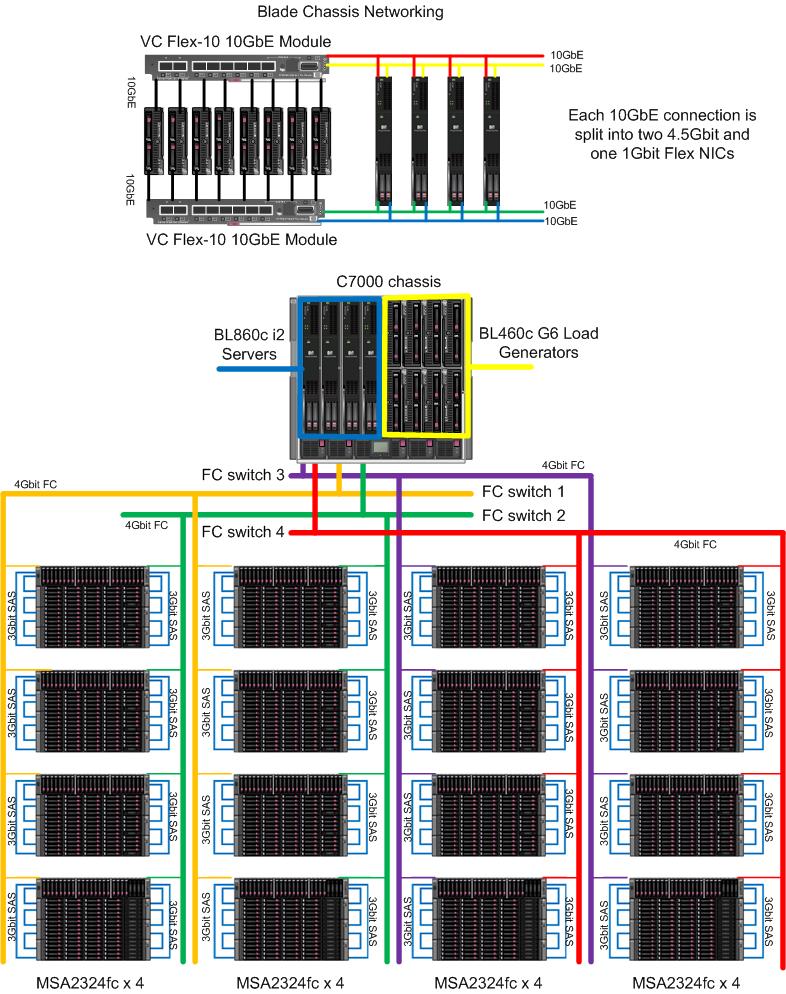
Network Configuration
|
Item No
|
Network Type
|
Number of Ports Used
|
Notes
|
|
1
|
Jumbo 10 Gigabit Ethernet
|
16
|
There are four 10Gbit ports per blade. Each 10Gbit port was carved up into two 4.5Gbit ports and a single 1Gbit port using HP's Flex-10 technology. The 4.5Gbit Flex-10 ports were all used to service the benchmark workload while the 1Gbit Flex-10 ports were for maintenance access and were not involved in benchmark activity.
|
Network Configuration Notes
There were two Virtual Connect Flex-10 10GbE modules configured in the c7000 blade chassis. Dual modules were used for redundancy, both were active. The first module connected internally to the "even" 10Gbit ports on each BL860c i2 blade. The second module connected internally to the "odd" 10Gbit ports on each BL860c i2 blade. Each physical 10Gbit port was divided into three logical ports with bandwidths of 4.5 gbit/s, 4.5 gbit/s, and 1 gbit/s using HP's Flex-10 technology. The 4.5 gbit ports carried the benchmark traffic while the 1 gbit ports were used for maintenence. HP-UX's Auto Port Aggregation (APA) software was used to create highly available (HA) network pairs from the 4.5 gbit Flex-NICs. Pairs were chosen such that the two virtual ports don't reside on the same physical port and each port connects to a different VC Flex-10 module. Four APA pairs in total were created per blade. Only one port in an APA pair was active, the other acted as a standby port in the event of some failure on the first port. All APA interfaces were configured to use jumbo frames (MTU size of 9000 bytes). All clients connected through the VC Flex-10 modules as well. The clients also had their 10Gbit links divided into two 4.5Gbit logical ports and one 1Gbit logical port.
Benchmark Network
An MTU size of 9000 was set for all connections to the benchmark environment (load generators and blade servers). Each load generator connected to the network via its dual on-board 10GbE ports. Each blade server had four APA interfaces configured which combined two virtual 4.5 Gbit server ports in an active/standby combination. Each APA interface on the blade was then assigned an IP address in a separate IP subnet, so four IP subnets were configured on each blade. The same IP subnets were used across all four blades. Each load generator had a Flex 4.5Gbit network connection to each of the four IP subnets (two from each 10GbE connection). Each load generator sends requests to, and receives responses from, all active server interfaces.
Processing Elements
|
Item No
|
Qty
|
Type
|
Description
|
Processing Function
|
|
1
|
8
|
CPU
|
Intel Itanium Model 9350, 1.73Ghz with 24M L3 cache
|
NFS protocol, VxFS filesystem, Networking, Serviceguard
|
|
2
|
32
|
NA
|
MSA2324fc array controller
|
RAID, write cache mirroring, disk scrubbing
|
Processing Element Notes
Each BL860c i2 blade has two physical processors, each with four cores and two threads per core.
Memory
|
Description
|
Size in GB
|
Number of Instances
|
Total GB
|
Nonvolatile
|
|
Blade server main memory
|
192
|
4
|
768
|
V
|
|
Disk array controller's main memory, 1GB per controller
|
2
|
16
|
32
|
NV
|
|
Grand Total Memory Gigabytes
|
|
|
800
|
|
Memory Notes
Each storage array has dual controller units that work as an active-active fail-over pair. Writes are mirrored between the controller pairs. In the event of a power failure, the modified cache contents are backed up to Flash memory utilizing the power from a super capacitor. The Flash memory module can save the contents of the cache indefinitely. In the event of a controller failure, the other controller unit is capable of saving all state that was managed by the first (and vise versa). When one of the controllers has failed, the other controller turns off its write cache and writes directly to disk before acknowledging any write operations. If a super capacitor failure happens on a controller, then the write cache will also be disabled.
Stable Storage
NFS stable write and commit operations are not acknowledged until after the MSA2324fc array has acknowledged the data is stored in stable storage. The MSA2324fc has dual controllers that operate in an active-active fail-over pair. Writes are mirrored between controllers and a super capacitor + Flash is used to save the cache contents indefinitely in the event of power failure. If either a controller or super capacitor fail, then acknowledgement of writes does not occur until the written data reaches the disk.
System Under Test Configuration Notes
The system under test consisted of four Integrity BL860c i2 blades using 192GB of memory each. The blades were configured in an active-active cluster fail-over configuration using HP's Serviceguard HA software which comes standard with the HP-UX High Availability Operating Environment. Each BL860c i2 contained two dual-port 8Gbit FC PCIe cards (4 ports total). Each BL860c i2 also had two built-in dual-port 10GbE controllers (4 ports total). The BL860c i2 blades were contained within a single c7000 chassis configured with two Virtual Connect Flex-10 10Gb Ethernet Modules and four 8Gbit FC switches. The VC Flex-10 module in I/O bay #1 connected to the even ports of all the built-in 10GbE interfaces. The VC Flex-10 in I/O bay #2 connected to the odd ports of all the 10GbE interfaces. Each FC port on a BL860c i2 blade server connects to a different FC port on the internal FC switches (4 ports connect to 4 switches). Eight of the external ports on FC switch 1 connect to the A controller on eight of the arrays. Eight of the external ports on the FC switch 2 connect to the B controller on those same eight arrays. Eight of the external ports on FC switch 3 connect to the A controllers on the remaining 8 arrays. Eight of the external ports on FC switch 4 connect to the B controllers on those remaining eight arrays. Each MSA2324fc connected to the blade chassis is fully redundant.
Other System Notes
Test Environment Bill of Materials
|
Item No
|
Qty
|
Vendor
|
Model/Name
|
Description
|
|
1
|
8
|
HP
|
Proliant BL460c G6
|
Half height blade server with 32GB RAM and the RedHat 5.3 Enterprise Linux operating system
|
Load Generators
|
LG Type Name
|
LG1
|
|
BOM Item #
|
1
|
|
Processor Name
|
Intel Xeon E5520 2.27Ghz 8MB L3
|
|
Processor Speed
|
2.27 GHz
|
|
Number of Processors (chips)
|
2
|
|
Number of Cores/Chip
|
4
|
|
Memory Size
|
32 GB
|
|
Operating System
|
RedHat Enterprise Linux 5.3
|
|
Network Type
|
Built-in dual-port 10GbE
|
Load Generator (LG) Configuration
Benchmark Parameters
|
Network Attached Storage Type
|
NFS V3
|
|
Number of Load Generators
|
8
|
|
Number of Processes per LG
|
192
|
|
Biod Max Read Setting
|
2
|
|
Biod Max Write Setting
|
2
|
|
Block Size
|
AUTO
|
Testbed Configuration
|
LG No
|
LG Type
|
Network
|
Target Filesystems
|
Notes
|
|
1..8
|
LG1
|
1
|
/n1_1,/n2_1,/n3_1,/n4_1,/n1_2,/n2_2,/n3_2,/n4_2,/n1_3,/n2_3,/n3_3,/n4_3,/n1_4,/n2_4,/n3_4,/n4_4
|
N/A
|
Load Generator Configuration Notes
All filesystems were mounted on all clients, which were connected to the same physical and logical network. Turned off TPA for the bnx2x driver by adding the line "options bnx2x disable_tpa=1" to the /etc/modprobe.conf file on each driver. The 1.48.107 version of the bnx2x driver was used.
Uniform Access Rule Compliance
Each client mounts all filesystems exported by the blade cluster.
Other Notes
Config Diagrams
Generated on Fri Jul 02 11:19:34 2010 by SPECsfs2008 HTML Formatter
Copyright © 1997-2008 Standard Performance Evaluation Corporation
First published at SPEC.org on 19-May-2010
{kind=link}