There are several things you must set up on your server before you can successfully execute a benchmark run.
Configure enough disk space. SPECsfs needs 10 MB of disk space for each NFSops you will be generating, with space for 10% growth during a typical benchmark run (10 measured load levels, 5 minutes per measured load). You may mount your test disks anywhere in your server's file space that is convenient for you. The NFSops a server can process is often limited by the number of independent disk drives configured on the server. In the past, a disk drive could generally sustain on the order of 100-200 NFSops. This was only a rule of thumb, and this value will change as new technologies become available. However, you will need to ensure you have sufficient disks configured to sustain the load you intend to measure.
Initialize and mount all file systems. According to the Run and Disclosure Rules, you must completely initialize all file systems you will be measuring before every benchmark run. On Unix systems, this is accomplished with the newfs command. Just deleting all files on the test disks in not sufficient because there can be lingering effects of the old files (e.g. the size of directory files, location of inodes on the disk) which effect the performance of the server. The only way to ensure a repeatable measurement is to re-initialize all data structures on the disks between benchmark runs. However, if you are not planning on disclosing the result, you do not need to perform this step.
Export all file systems to all clients. This gives the clients permission to mount, read, and write to your test disks. The benchmark program will fail without this permission.
Verify that all RPC services work. The benchmark programs use port mapping, mount, and NFS services provided by the server. The benchmark will fail if these services do not work for all clients on all networks. If your client systems have NFS client software installed, one easy way to do this is to attempt mounting one or more of the server's disks on the client. NFS servers generally allow you to tune the number of resources to handle UDP and/or TCP requests. When benchmarking using the TCP protocol , you must make sure that UDP support is at least minimally configured or the benchmark will fail to initialize.
Ensure your server is idle. Any other work being performed by your server is likely to perturb the measured throughput and response time. The only safe way to make a repeatable measurement is to stop all non-benchmark related processing on your server during the benchmark run.
Ensure that your test network is idle. Any extra traffic on your network will make it difficult to reproduce your results, and will probably make your server look slower. The easiest thing to do is to have a separate, isolated network between the clients and the server during the test.
At this point, your server should be ready to measure. You must now set up a few things on your client systems so they can run the benchmark programs.
Create "spec" user. SPECsfs should run as a non-root user.
The SPECsfs programs must be installed on clients.
Ensure sfs and sfs3 are setUID root, if necessary. Some NFS servers only accept mount requests if sent from a reserved UDP or TCP port, and only the root user can send packets from reserved ports. Since SPECsfs generally is run as a non-root user, the sfs and sfs3 programs must be set to execute with an effective UID of root. To get the benchmark to use a reserved port, you must include a -DRESVPORT option in your compile command. This is easiest to accomplish by editing the Makefile wrapper file (M.xxxx) for your client systems. The build process will then make the client use a reserved port and will arrange to run the benchmark programs as root. However, you may want to verify this works the first time you try it.
Configure and verify network connectivity between all clients and server. Clients must be able to send IP packets to each other and to the server. How you configure this is system-specific and is not described in this document. Two easy ways to verify network connectivity are to use a "ping" program or the netperf benchmark (http://onet1.external.hp.com/netperf/NetperfPage.html).
If clients have NFS client code, verify they can mount and access server file systems. This is another good way to verify your network is properly configured. You should unmount the server's test disks before running the benchmark.
Configure remote shell access. The Prime Client needs to be able to execute commands on the other client systems using rsh (remsh on HP-UX, AT&T Unix, and Unicos). For this to work, you need to create a .rhosts file in the spec user's home directory.
A good test of this is to execute this command from the prime client:
$ rsh client_name "rsh prime_client date"If this works, all is well.
The Prime Client must have sufficient file space in the SFS file tree to hold the result and log files for a run. Each run generates a log file of 10 to 100 kilobytes, plus a result file of 10 to 100 kilobytes. Each client also generates a log file of one to 10 kilobytes.
Once you have the clients and server configured, you must set some parameters for the benchmark itself, which you do in a file called the "rc file". The actual name of the file is a prefix picked by you, and the suffix "_rc". The default version shipped with the benchmark is delivered as "sfs_rc" in the benchmark source directory. The SPECsfs tools allow you to modify parameters in the rc file. If you want to manually edit this file, the sfs_rc file should be copied to the results directory. The sfs_rc file can then be edited directly. The sfs_rc file is executed by a Bourne shell program, so all the lines in the RC file must be in Bourne shell format. Most important, any variable which is a list of values must have its value enclosed in double quotes. There are several parameters you must set, and several others you may change to suit your needs while performing a disclosable run. There are also many other parameters you may change which change the benchmark behavior, but lead to an undisclosable run (for example, turning on debug logging).
The parameters you can/must set are:
client_name server:path server:path...
client_name server:path server:path...
And so on, one line for each client system. This file gets stored in the
"results" directory, the same place as the rc file.
There are many other parameters you can modify in the rc file, but generally none are necessary. They allow you to change the NFS operation mix, change run duration parameters, or turn on debugging information. Modifying most of these parameters will lead to an invalid (that is, undisclosable) run. The full list of parameters is documented at the end of the sfs_rc file and at the end of this section.
The most common way to perform an undiscloseable run is to violate the uniform access rule. (See "SPEC's Description of Uniform Access for SFS 3.0".) In some systems, it is possible to complete an NFS operation especially fast if the request is made through one network interface and the data is stored on just the right file system. The intent of the rule is to prevent the benchmarker (that's you) from taking advantage of these fast paths to get an artificially good result. The specific wording of the rule states that "for every network, all file systems should be accessed by all clients uniformly." The practical implication of the uniform access rule is you must be very careful with the order in which you specify mount points in the MNT_POINTS variable. The fool-proof way to comply with the uniform access rule is to have every client access every file system, evenly spreading the load across the network paths between the client and server. This works pretty well for small systems, but may require more procs per client than you want to use when testing large servers. If you want to run fewer procs on your clients' than you have file systems, you will need to take some care figuring out the mount points for each client. Uniform access is a slippery subject. It is much easier to examine a configuration and say whether it is uniform than it is to come up with a perfect algorithm for generating complying mount point lists. There will always be new configurations invented which do not fit any of the examples described below. You must always examine the access patterns and verify there is nothing new and innovative about your systems which makes it accidentally violate the uniform access rule. Below are some examples of generating mount point lists which do comply with the uniform access rule.
To begin, you must first determine the number of file systems, clients, and load generating processes you will be using. Once you have that, you can start deciding how to assign procs to file systems. As a first example, we will use the following file server:
Clients C1 and C2 are attached to Network1, and the server's address on
that net is S1. It has two disk controllers (DC1 and DC2), with four file
systems attached to each controller (F1 through F8).
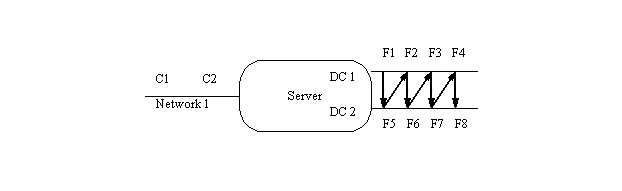
You start by assigning F1 to proc1 on client 1. That was the easy part. You next switch to DC2 and pick the first unused file system (F5). Assign this to client 1, proc 2. Continue assigning file systems to client 1, each time switching to a different disk controller and picking the next unused disk on that controller, until client 1 has PROC file systems. In the picture above, you will be following a zig-zag pattern from the top row to the bottom, then up to the top again. If you had three controllers, you would hit the top, then middle, then bottom controller, then move back to the top again. When you run out of file systems on a single controller, go back and start reusing them, starting from the first one. Now that client 1 has all its file systems, pick the next controller and unused file system (just like before) and assign this to client 2. Keep assigning file systems to client 2 until it also has PROC file systems. If there were a third client, you would keep assigning it file systems, like you did for client 2. If you look at the result in tabular form, it looks something like this (assuming 4 procs per client):
C1: S1:F1 S1:F5 S1:F2 S1:F6 C2: S1:F3 S1:F7 S1:F4 S1:F8
The above form is how you would specify the mount points in a file. If you wanted to specify the mount points in the RC file directly, then it would look like this:
CLIENTS="C1 C2" PROCS=4 MNT_POINTS="S1:F1 S1:F5 S1:F2 S1:F6 S1:F3 S1:F7 S1:F4 S1:F8"
If we had 6 procs per client, it would look like this:
C1: S1:F1 S1:F5 S1:F2 S1:F6 S1:F3 S1:F7 C2: S1:F4 S1:F8 S1:F1 S1:F5 S1:F2 S1:F6
Note that file systems F1, F2, F5, and F6 each get loaded by two procs (one from each client) and the remainder get loaded by one proc each. Given the total number of procs, this is as uniform as possible. In a real benchmark configuration, it is rarely useful to have an unequal load on a given disk, but there might be some reasons this makes sense.
The next wrinkle comes if you should have more than one network interface
on your server, like so:
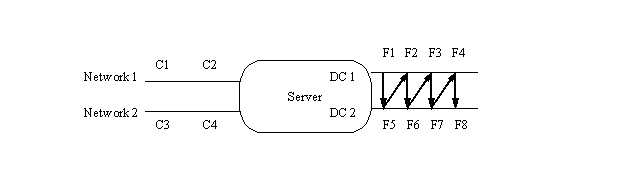
Clients C1 and C2 are on Network1, and the server's address is S1. Clients C3 and C4 are on Network2, and the server's address is S2. We start with the same way, assigning F1 to proc 1 of C1, then assigning file systems to C1 by rotating through the disk controllers and file systems. When C1 has PROC file systems, we then switch to the next client on the same network, and continue assigning file systems. When all clients on that network have file systems, switch to the first client on the next network, and keep going. Assuming two procs per client, the result is:
C1: S1:F1 S1:F5 C2: S1:F2 S1:F6 C3: S2:F3 S2:F7 C4: S2:F4 S2:F8
And the mount point list is:
MNT_POINTS="S1:F1 S1:F5 S1:F3 S1:F7 S2:F2 S2:F6 S2:F4 S2:F8"
The first two mount points are for C1, the second two for C2, and so forth. These examples are meant to be only that, examples. There are more complicated configurations which will require you to spend some time analyzing the configuration and assuring yourself (and possibly SPEC) that you have achieved uniform access. You need to examine each component in your system and answer the question "is the load seen by this component coming uniformly from all the upstream components, and is it being passed along in a uniform manner to the downstream ones?" If the answer is yes, then you are probably in compliance.
As mentioned above, there are many more parameters you can set in the RC file. Here is the list and what they do. The following options may be set and still yield a discloseable benchmark run:
SFS MIXFILE VERSION 2
opname xx%
opname yy%
# comment
opname xx%
The first line must be the exact string "SFS MIXFILE VERSION 2"
and nothing else. The subsequent lines are either comments (denoted with
a hash character in the first column) or the name of an operation and its
percentage in the mix (one to three digits, followed by a percent
character). The operation names are: null, getattr,
setattr, root, lookup, readlink, read, wrcache, write, create, remove,
rename, link, symlink, mkdir, rmdir, readdir, fsstat, access, commit,
fsinfo, mknod, pathconf, and readdirplus. The total percentages
must add up to 100 percent.
| Value | Name of flag | Comment |
|---|---|---|
| 1 | DEBUG_NEW_CODE | Obsolete and unused |
| 2 | DEBUG_PARENT_GENERAL | Information about the parent process running on each client system. |
| 3 | DEBUG_PARENT_SIGNAL | Information about signals between the parent process and child processes |
| 4 | DEBUG_CHILD_ERROR | Information about failed NFS operations |
| 5 | DEBUG_CHILD_SIGNAL | Information about signals received by the child processes |
| 6 | DEBUG_CHILD_XPOINT | Every 10 seconds, the benchmark checks its progress versus how well it's supposed to be doing (for example, verifying it is hitting the intended operation rate). This option gives you information about each checkpoint |
| 7 | DEBUG_CHILD_GENERAL | Information about the child in general |
| 8 | DEBUG_CHILD_OPS | Information about operation starts, stops, and failures |
| 9 | DEBUG_CHILD_FILES | Information about what files the child is accessing |
| 10 | DEBUG_CHILD_RPC | Information about the actual RPCs generated and completed by the child |
| 11 | DEBUG_CHILD_TIMING | Information about the amount of time a child process spends sleeping to pace itself |
| 12 | DEBUG_CHILD_SETUP | Information about the files, directories, and mix percentages used by a child process |
| 13 | DEBUG_CHILD_FIT | Information about the child's algorithm to find files of the appropriate size for a given operation |
The following are things that one may wish to adjust to obtain the maximum throughput for the SUT.